Releases: roboflow/supervision
supervision-0.25.0
Supervision 0.25.0 is here! Featuring a more robust LineZone crossing counter, support for tracking KeyPoints, Python 3.13 compatibility, and 3 new metrics: Precision, Recall and Mean Average Recall. The update also includes smart label positioning, improved Oriented Bounding Box support, and refined error handling. Thank you to all contributors - especially those who answered the call of Hacktoberfest!
Changelog
🚀 Added
- Essential update to the
LineZone: when computing line crossings, detections that jitter might be counted twice (or more!). This can now be solved with theminimum_crossing_thresholdargument. If you set it to2or more, extra frames will be used to confirm the crossing, improving the accuracy significantly. (#1540)
hb-final.mp4
- It is now possible to track objects detected as
KeyPoints. See the complete step-by-step guide in the Object Tracking Guide. (#1658)
import numpy as np
import supervision as sv
from ultralytics import YOLO
model = YOLO("yolov8m-pose.pt")
tracker = sv.ByteTrack()
trace_annotator = sv.TraceAnnotator()
def callback(frame: np.ndarray, _: int) -> np.ndarray:
results = model(frame)[0]
key_points = sv.KeyPoints.from_ultralytics(results)
detections = key_points.as_detections()
detections = tracker.update_with_detections(detections)
annotated_image = trace_annotator.annotate(frame.copy(), detections)
return annotated_image
sv.process_video(
source_path="input_video.mp4",
target_path="output_video.mp4",
callback=callback
)track-keypoints-with-smoothing.mp4
See the guide for the full code used to make the video
-
Added
is_emptymethod toKeyPointsto check if there are any keypoints in the object. (#1658) -
Added
as_detectionsmethod toKeyPointsthat convertsKeyPointstoDetections. (#1658) -
Added a new video to
supervision[assets]. (#1657)
from supervision.assets import download_assets, VideoAssets
path_to_video = download_assets(VideoAssets.SKIING)- Supervision can now be used with
Python 3.13. The most renowned update is the ability to run Python without Global Interpreter Lock (GIL). We expect support for this among our dependencies to be inconsistent, but if you do attempt it - let us know the results! (#1595)

- Added
Mean Average RecallmAR metric, which returns a recall score, averaged over IoU thresholds, detected object classes, and limits imposed on maximum considered detections. (#1661)
import supervision as sv
from supervision.metrics import MeanAverageRecall
predictions = sv.Detections(...)
targets = sv.Detections(...)
map_metric = MeanAverageRecall()
map_result = map_metric.update(predictions, targets).compute()
map_result.plot()
- Added
PrecisionandRecallmetrics, providing a baseline for comparing model outputs to ground truth or another model (#1609)
import supervision as sv
from supervision.metrics import Recall
predictions = sv.Detections(...)
targets = sv.Detections(...)
recall_metric = Recall()
recall_result = recall_metric.update(predictions, targets).compute()
recall_result.plot()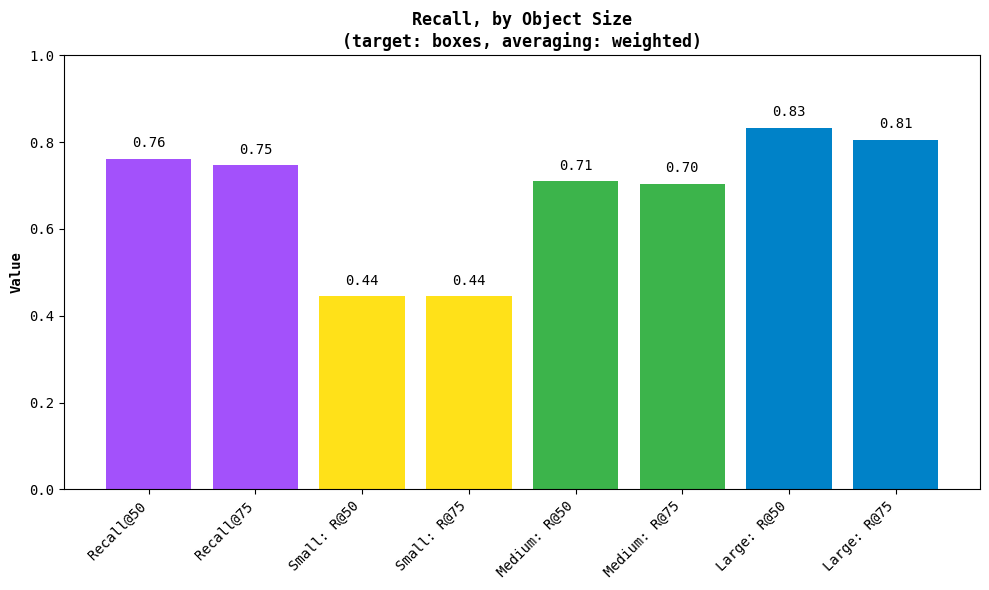
- All Metrics now support Oriented Bounding Boxes (OBB) (#1593)
import supervision as sv
from supervision.metrics import F1_Score
predictions = sv.Detections(...)
targets = sv.Detections(...)
f1_metric = MeanAverageRecall(metric_target=sv.MetricTarget.ORIENTED_BOUNDING_BOXES)
f1_result = f1_metric.update(predictions, targets).compute()
- Introducing Smart Labels! When
smart_positionis set forLabelAnnotator,RichLabelAnnotatororVertexLabelAnnotator, the labels will move around to avoid overlapping others. (#1625)
import supervision as sv
from ultralytics import YOLO
image = cv2.imread("image.jpg")
label_annotator = sv.LabelAnnotator(smart_position=True)
model = YOLO("yolo11m.pt")
results = model(image)[0]
detections = sv.Detections.from_ultralytics(results)
annotated_frame = label_annotator.annotate(first_frame.copy(), detections)
sv.plot_image(annotated_frame)fish-z.mp4
- Added the
metadatavariable toDetections. It allows you to store custom data per-image, rather than per-detected-object as was possible withdatavariable. For example,metadatacould be used to store the source video path, camera model or camera parameters. (#1589)
import supervision as sv
from ultralytics import YOLO
model = YOLO("yolov8m")
result = model("image.png")[0]
detections = sv.Detections.from_ultralytics(result)
# Items in `data` must match length of detections
object_ids = [num for num in range(len(detections))]
detections.data["object_number"] = object_ids
# Items in `metadata` can be of any length.
detections.metadata["camera_model"] = "Luxonis OAK-D"- Added a
py.typedtype hints metafile. It should provide a stronger signal to type annotators and IDEs that type support is available. (#1586)
🌱 Changed
ByteTrackno longer requiresdetectionsto have aclass_id(#1637)draw_line,draw_rectangle,draw_filled_rectangle,draw_polygon,draw_filled_polygonandPolygonZoneAnnotatornow comes with a default color (#1591)- Dataset classes are treated as case-sensitive when merging multiple datasets. (#1643)
- Expanded metrics documentation with example plots and printed results (#1660)
- Added usage example for polygon zone (#1608)
- Small improvements to error handling in polygons: (#1602)
🔧 Fixed
- Updated
ByteTrack, removing shared variables. Previously, multiple instances ofByteTrackwould share some date, requiring liberal use oftracker.reset(). (#1603), (#1528) - Fixed a bug where
class_agnosticsetting inMeanAveragePrecisionwould not work. (#1577) hacktoberfest - Removed welcome workflow from our CI system. (#1596)
✅ No removals or deprecations this time!
⚙️ Internal Changes
- Large refactor of
ByteTrack(#1603)- STrack moved to separate class
- Remove superfluous
BaseTrackclass - Removed unused variables
- Large refactor of
RichLabelAnnotator, matching its contents withLabelAnnotator. (#1625)
🏆 Contributors
@onuralpszr (Onuralp SEZER), @kshitijaucharmal (KshitijAucharmal), @grzegorz-roboflow (Grzegorz Klimaszewski), @Kadermiyanyedi (Kader Miyanyedi), @PrakharJain1509 ([Pra...
Contributors
Assets 2
supervision-0.24.0
Supervision 0.24.0 is here! We've added many new changes, including the F1 score, enhancements to LineZone, EasyOCR support, NCNN support, and the best Cookbook to date! You can also try out our annotators directly in the browser. Check out the release notes to find out more!
📢 Announcements

-
Supervision is celebrating Hacktoberfest! Whether you're a newcomer to open source or a veteran contributor, we welcome you to join us in improving
supervision. You can grab any issue without an assigned contributor: Hacktoberfest Issues Board. We'll be adding many more issues next week! 🎉 -
We recently launched the Model Leaderboard. Come check how the latest models perform! It is also open-source, so you can contribute to it as well! 🚀
Changelog
🚀 Added
- Added F1 score as a new metric for detection and segmentation. The F1 score balances precision and recall, providing a single metric for model evaluation. #1521
import supervision as sv
from supervision.metrics import F1Score
predictions = sv.Detections(...)
targets = sv.Detections(...)
f1_metric = F1Score()
f1_result = f1_metric.update(predictions, targets).compute()
print(f1_result)
print(f1_result.f1_50)
print(f1_result.small_objects.f1_50)
- Added new cookbook: Small Object Detection with SAHI. This cookbook provides a detailed guide on using
InferenceSlicerfor small object detection, and is one of the best cookbooks we've ever seen. Thank you @ediardo! #1483


- You can now try supervision annotators on your own images. Check out the annotator docs. The preview is powered by an Embedded Workflow. Thank you @joaomarcoscrs! #1533

- Enhanced
LineZoneAnnotator, allowing the labels to align with the line, even when it's not horizontal. Also, you can now disable text background, and choose to draw labels off-center which minimizes overlaps for multipleLineZonelabels. Thank you @jcruz-ferreyra! #854
import supervision as sv
import cv2
image = cv2.imread("<SOURCE_IMAGE_PATH>")
line_zone = sv.LineZone(
start=sv.Point(0, 100),
end=sv.Point(50, 200)
)
line_zone_annotator = sv.LineZoneAnnotator(
text_orient_to_line=True,
display_text_box=False,
text_centered=False
)
annotated_frame = line_zone_annotator.annotate(
frame=image.copy(), line_counter=line_zone
)
sv.plot_image(frame)sheep_1_out_optim.mp4
- Added per-class counting capabilities to
LineZoneand introducedLineZoneAnnotatorMulticlassfor visualizing the counts per class. This feature allows tracking of individual classes crossing a line, enhancing the flexibility of use cases like traffic monitoring or crowd analysis. #1555
import supervision as sv
import cv2
image = cv2.imread("<SOURCE_IMAGE_PATH>")
line_zone = sv.LineZone(
start=sv.Point(0, 100),
end=sv.Point(50, 200)
)
line_zone_annotator = sv.LineZoneAnnotatorMulticlass()
frame = line_zone_annotator.annotate(
frame=frame, line_zones=[line_zone]
)
sv.plot_image(frame)street_out_optim.mp4
- Added
from_easyocr, allowing integration of OCR results into the supervision framework. EasyOCR is an open-source optical character recognition (OCR) library that can read text from images. Thank you @onuralpszr! #1515
import supervision as sv
import easyocr
import cv2
image = cv2.imread("<SOURCE_IMAGE_PATH>")
reader = easyocr.Reader(["en"])
result = reader.readtext("<SOURCE_IMAGE_PATH>", paragraph=True)
detections = sv.Detections.from_easyocr(result)
box_annotator = sv.BoxAnnotator(color_lookup=sv.ColorLookup.INDEX)
label_annotator = sv.LabelAnnotator(color_lookup=sv.ColorLookup.INDEX)
annotated_image = image.copy()
annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections)
annotated_image = label_annotator.annotate(scene=annotated_image, detections=detections)
sv.plot_image(annotated_image)
- Added
oriented_box_iou_batchfunction todetection.utils. This function computes Intersection over Union (IoU) for oriented or rotated bounding boxes (OBB), making it easier to evaluate detections with non-axis-aligned boxes. Thank you @patel-zeel! #1502
import numpy as np
boxes_true = np.array([[[1, 0], [0, 1], [3, 4], [4, 3]]])
boxes_detection = np.array([[[1, 1], [2, 0], [4, 2], [3, 3]]])
ious = sv.oriented_box_iou_batch(boxes_true, boxes_detection)
print("IoU between true and detected boxes:", ious)Note: the IoU is approximated as mask IoU.

-
Extended
PolygonZoneAnnotatorto allow setting opacity when drawing zones, providing enhanced visualization by filling the zone with adjustable transparency. Thank you @grzegorz-roboflow! #1527 -
Added
from_ncnn, a connector for the NCNN. It is a powerful object detection framework from Tencent, written from ground-up in C++, with no third party dependencies. Thank you @onuralpszr! #1524
import cv2
from ncnn.model_zoo import get_model
import supervision as sv
image = cv2.imread("<SOURCE_IMAGE_PATH>")
model = get_model(
"yolov8s",
target_size=640,
prob_threshold=0.5,
nms_threshold=0.45,
num_threads=4,
use_gpu=True,
)
result = model(image)
detections = sv.Detections.from_ncnn(result)🌱 Changed
-
Supervision now depends on
opencv-pythonrather thanopencv-python-headless. #1530 -
Fixed broken or outdated links in documentation and notebooks, improving navigation and ensuring accuracy of references. Thanks to @capjamesg for identifying these issues. #1523
-
Enabled and fixed Ruff rules for code formatting, including changes like avoiding unnecessary iterable allocations and using Optional for default mutable arguments. #1526
🔧 Fixed
-
Updated the COCO 101 point Average Precision algorithm to correctly interpolate precision, providing a more precise calculation of average precision without averaging out intermediate values. #1500
-
Resolved miscellaneous issues highlighted when building documentation. This mostly includes whitespace adjustments and type inconsistencies. Updated documentation for clarity and fixed formatting issues. Added explicit version for
mkdocstrings-python. #1549 -
Clarified documentation around the
overlap_ratio_whargument deprecation inInferenceSlicer. #1547
✅ No deprecations this time!
❌ Removed
- The
frame_resolution_whparameter inPolygonZonehas been removed due to deprecation. - Supervision installation methods "headless" and "desktop" removed, as they are no longer needed.
pip install supervision[headless]will install the base library and warn of non-existent extra.
🏆 Contributors
@onuralpszr (Onuralp SEZER), @joaomarcoscrs (João Marcos Cardoso Ramos da Silva), @jcruz-ferreyra (Juan Cruz), @patel-zeel (Zeel B Patel), @grzegorz-roboflow (Grzegorz Klimaszewski), @Kadermiyanyedi (Kader Miyanyedi), @ediardo (Eddie Ramirez), @CharlesCNorton, @ethanwhite (Ethan...
Contributors
Assets 2
supervision-0.23.0
🚀 Added
BackgroundOverlayAnnotatorannotates the background of your image! #1385
pexels-squirrel-short-result-optim.mp4
(video by Pexels)
- We're introducing metrics, which currently supports
xyxyboxes and masks. Over the next few releases,supervisionwill focus on adding more metrics, allowing you to evaluate your model performance. We plan to support not just boxes, masks, but oriented bounding boxes as well! #1442
Tip
Help in implementing metrics is very welcome! Keep an eye on our issue board if you'd like to contribute!
import supervision as sv
from supervision.metrics import MeanAveragePrecision
predictions = sv.Detections(...)
targets = sv.Detections(...)
map_metric = MeanAveragePrecision()
map_result = map_metric.update(predictions, targets).compute()
print(map_result)
print(map_result.map50_95)
print(map_result.large_objects.map50_95)
map_result.plot()Here's a very basic way to compare model results:
📊 Example code
import supervision as sv
from supervision.metrics import MeanAveragePrecision
from inference import get_model
import matplotlib.pyplot as plt
# !wget https://media.roboflow.com/notebooks/examples/dog.jpeg
image = "dog.jpeg"
model_1 = get_model("yolov8n-640")
model_2 = get_model("yolov8s-640")
model_3 = get_model("yolov8m-640")
model_4 = get_model("yolov8l-640")
results_1 = model_1.infer(image)[0]
results_2 = model_2.infer(image)[0]
results_3 = model_3.infer(image)[0]
results_4 = model_4.infer(image)[0]
detections_1 = sv.Detections.from_inference(results_1)
detections_2 = sv.Detections.from_inference(results_2)
detections_3 = sv.Detections.from_inference(results_3)
detections_4 = sv.Detections.from_inference(results_4)
map_n_metric = MeanAveragePrecision().update([detections_1], [detections_4]).compute()
map_s_metric = MeanAveragePrecision().update([detections_2], [detections_4]).compute()
map_m_metric = MeanAveragePrecision().update([detections_3], [detections_4]).compute()
labels = ["YOLOv8n", "YOLOv8s", "YOLOv8m"]
map_values = [map_n_metric.map50_95, map_s_metric.map50_95, map_m_metric.map50_95]
plt.title("YOLOv8 Model Comparison")
plt.bar(labels, map_values)
ax = plt.gca()
ax.set_ylim([0, 1])
plt.show()
- Added the
IconAnnotator, which allows you to place icons on your images. #930
example-icon-annotator-optim.mp4
(Video by Pexels, icons by Icons8)
import supervision as sv
from inference import get_model
image = <SOURCE_IMAGE_PATH>
icon_dog = <DOG_PNG_PATH>
icon_cat = <CAT_PNG_PATH>
model = get_model(model_id="yolov8n-640")
results = model.infer(image)[0]
detections = sv.Detections.from_inference(results)
icon_paths = []
for class_name in detections.data["class_name"]:
if class_name == "dog":
icon_paths.append(icon_dog)
elif class_name == "cat":
icon_paths.append(icon_cat)
else:
icon_paths.append("")
icon_annotator = sv.IconAnnotator()
annotated_frame = icon_annotator.annotate(
scene=image.copy(),
detections=detections,
icon_path=icon_paths
)- Segment Anything 2 was released this month. And while you can load its results via
from_sam, we've added support tofrom_ultralyticsfor loading the results if you ran it with Ultralytics. #1354
import cv2
import supervision as sv
from ultralytics import SAM
image = cv2.imread("...")
model = SAM("mobile_sam.pt")
results = model(image, bboxes=[[588, 163, 643, 220]])
detections = sv.Detections.from_ultralytics(results[0])
polygon_annotator = sv.PolygonAnnotator()
mask_annotator = sv.MaskAnnotator()
annoated_image = mask_annotator.annotate(image.copy(), detections)
annoated_image = polygon_annotator.annotate(annoated_image, detections)
sv.plot_image(annoated_image, (12,12))SAM2 with our annotators:
pexels_cheetah-result-optim-halfsized.mp4
TriangleAnnotatorandDotAnnotatorcontour color customization #1458VertexLabelAnnotatorfor keypoints now hastext_colorparameter #1409
🌱 Changed
- Updated
sv.Detections.from_transformersto support thetransformers v5functions. This includes theDetrImageProcessormethodspost_process_object_detection,post_process_panoptic_segmentation,post_process_semantic_segmentation, andpost_process_instance_segmentation. #1386 InferenceSlicernow features anoverlap_ratio_whparameter, making it easier to compute slice sizes when handling overlapping slices. #1434
image_with_small_objects = cv2.imread("...")
model = get_model("yolov8n-640")
def callback(image_slice: np.ndarray) -> sv.Detections:
print("image_slice.shape:", image_slice.shape)
result = model.infer(image_slice)[0]
return sv.Detections.from_inference(result)
slicer = sv.InferenceSlicer(
callback=callback,
slice_wh=(128, 128),
overlap_ratio_wh=(0.2, 0.2),
)
detections = slicer(image_with_small_objects)🛠️ Fixed
- Annotator type fixes #1448
- New way of seeking to a specific video frame, where other methods don't work #1348
plot_imagenow clearly states the size is in inches. #1424
⚠️ Deprecated
overlap_filter_strategyinInferenceSlicer.__init__is deprecated and will be removed insupervision-0.27.0. Useoverlap_strategyinstead.overlap_ratio_whinInferenceSlicer.__init__is deprecated and will be removed insupervision-0.27.0. Useoverlap_whinstead.
❌ Removed
- The
track_buffer,track_thresh, andmatch_threshparameters inByteTrackare deprecated and were removed as ofsupervision-0.23.0. Uselost_track_buffer,track_activation_threshold, andminimum_matching_thresholdinstead. - The
triggering_positionparameter insv.PolygonZonewas removed as ofsupervision-0.23.0. Usetriggering_anchorsinstead.
🏆 Contributors
@shaddu, @onuralpszr (Onuralp SEZER), @Kadermiyanyedi (Kader Miyanyedi), @xaristeidou (Christoforos Aristeidou), @Gk-rohan (Rohan Gupta), @Bhavay-2001 (Bhavay Malhotra), @arthurcerveira (Arthur Cerveira), @J4BEZ (Ju Hoon Park), @venkatram-dev, @eric220, @capjamesg (James), @yeldarby (Brad Dwyer), @SkalskiP (Piotr Skalski), @LinasKo (LinasKo)
Contributors
Assets 2
supervision-0.22.0
🚀 Added

sv.KeyPoints.from_mediapipeadding support for Mediapipe keypoint models (both legacy and modern), along with default visualizers for face and body pose keypoints. (#1232, #1316)
import numpy as np
import mediapipe as mp
import supervision as sv
from PIL import Image
model = mp.solutions.face_mesh.FaceMesh()
edge_annotator = sv.EdgeAnnotator(color=sv.Color.BLACK, thickness=2)
image = Image.open(<PATH_TO_IMAGE>).convert('RGB')
results = model.process(np.array(image))
key_points = sv.KeyPoints.from_mediapipe(results, resolution_wh=image.size)
annotated_image = edge_annotator.annotate(scene=image, key_points=key_points)IMG_1777-result-refined-optimized.mp4
-
sv.KeyPoints.from_detectron2andsv.Detections.from_detectron2extending support for Detectron2 models. (#1310, #1300) -
sv.RichLabelAnnotatorallowing to draw unicode characters (e.g. from non-latin languages), as long as you provide a compatible font. (#1277)
rich-label-annotator-2.mp4
🌱 Changed
sv.DetectionsDatasetandsv.ClassificationDatasetallowing to load the images into memory only when necessary (lazy loading). (#1326)
import roboflow
from roboflow import Roboflow
import supervision as sv
roboflow.login()
rf = Roboflow()
project = rf.workspace(<WORKSPACE_ID>).project(<PROJECT_ID>)
dataset = project.version(<PROJECT_VERSION>).download("coco")
ds_train = sv.DetectionDataset.from_coco(
images_directory_path=f"{dataset.location}/train",
annotations_path=f"{dataset.location}/train/_annotations.coco.json",
)
path, image, annotation = ds_train[0]
# loads image on demand
for path, image, annotation in ds_train:
# loads image on demandsv.Detections.from_lmmallowing to parse Florence-2 text result intosv.Detectionsobject. (#1296)

sv.DotAnnotatorandsv.TriangleAnnotatorallowing to add marker outlines. (#1294)
🛠️ Fixed
sv.ColorAnnotatorandsv.CropAnnotatorbuggy behaviours. (#1277, #1312)
🧑🍳 Cookbooks
This release, @onuralpszr added two new Cookbooks to our collection. Check them out to learn how to save Detections to a file and convert it back to Detections!
🏆 Contributors
@onuralpszr (Onuralp SEZER), @David-rn (David Redó), @jeslinpjames (Jeslin P James), @Bhavay-2001 (Bhavay Malhotra), @hardikdava (Hardik Dava), @kirilman, @dsaha21 (Dripto Saha), @cdragos (Dragos Catarahia), @mqasim41 (Muhammad Qasim), @SkalskiP (Piotr Skalski), @LinasKo (Linas Kondrackis)
Special thanks to @rolson24 (Raif Olson) for helping the community with ByteTrack!
Contributors
Assets 2
supervision-0.21.0
📅 Timeline
The supervision-0.21.0 release is around the corner. Here is the timeline:
5 Jun 2024 08:00 PM CEST (UTC +2) / 5 Jun 2024 11:00 AM PDT (UTC -7)- mergedevelopintomain- closing listsupervision-0.21.0features6 Jun 2024 11:00 AM CEST (UTC +2) / 6 Jun 2024 02:00 AM PDT (UTC -7)- releasesupervision-0.21.0
🪵 Changelog
🚀 Added
sv.Detections.with_nmmto perform non-maximum merging on the current set of object detections. (#500)

sv.Detections.from_lmmallowing to parse Large Multimodal Model (LMM) text result intosv.Detectionsobject. For nowfrom_lmmsupports only PaliGemma result parsing. (#1221)
import supervision as sv
paligemma_result = "<loc0256><loc0256><loc0768><loc0768> cat"
detections = sv.Detections.from_lmm(
sv.LMM.PALIGEMMA,
paligemma_result,
resolution_wh=(1000, 1000),
classes=['cat', 'dog']
)
detections.xyxy
# array([[250., 250., 750., 750.]])
detections.class_id
# array([0])sv.VertexLabelAnnotatorallowing to annotate every vertex of a keypoint skeleton with custom text and color. (#1236)
import supervision as sv
image = ...
key_points = sv.KeyPoints(...)
LABELS = [
"nose", "left eye", "right eye", "left ear",
"right ear", "left shoulder", "right shoulder", "left elbow",
"right elbow", "left wrist", "right wrist", "left hip",
"right hip", "left knee", "right knee", "left ankle",
"right ankle"
]
COLORS = [
"#FF6347", "#FF6347", "#FF6347", "#FF6347",
"#FF6347", "#FF1493", "#00FF00", "#FF1493",
"#00FF00", "#FF1493", "#00FF00", "#FFD700",
"#00BFFF", "#FFD700", "#00BFFF", "#FFD700",
"#00BFFF"
]
COLORS = [sv.Color.from_hex(color_hex=c) for c in COLORS]
vertex_label_annotator = sv.VertexLabelAnnotator(
color=COLORS,
text_color=sv.Color.BLACK,
border_radius=5
)
annotated_frame = vertex_label_annotator.annotate(
scene=image.copy(),
key_points=key_points,
labels=labels
)
-
sv.KeyPoints.from_inferenceandsv.KeyPoints.from_yolo_nasallowing to createsv.KeyPointsfrom Inference and YOLO-NAS result. (#1147 and #1138) -
sv.mask_to_rleandsv.rle_to_maskallowing for easy conversion between mask and rle formats. (#1163)

🌱 Changed
-
sv.InferenceSlicerallowing to select overlap filtering strategy (NONE,NON_MAX_SUPPRESSIONandNON_MAX_MERGE). (#1236) -
sv.InferenceSliceradding instance segmentation model support. (#1178)
import cv2
import numpy as np
import supervision as sv
from inference import get_model
model = get_model(model_id="yolov8x-seg-640")
image = cv2.imread(<SOURCE_IMAGE_PATH>)
def callback(image_slice: np.ndarray) -> sv.Detections:
results = model.infer(image_slice)[0]
return sv.Detections.from_inference(results)
slicer = sv.InferenceSlicer(callback = callback)
detections = slicer(image)
mask_annotator = sv.MaskAnnotator()
label_annotator = sv.LabelAnnotator()
annotated_image = mask_annotator.annotate(
scene=image, detections=detections)
annotated_image = label_annotator.annotate(
scene=annotated_image, detections=detections)
sv.LineZonemaking it 10-20 times faster, depending on the use case. (#1228)

sv.DetectionDataset.from_cocoandsv.DetectionDataset.as_cocoadding support for run-length encoding (RLE) mask format. (#1163)
🏆 Contributors
@onuralpszr (Onuralp SEZER), @LinasKo (Linas Kondrackis), @rolson24 (Raif Olson), @mario-dg (Mario da Graca), @xaristeidou (Christoforos Aristeidou), @ManzarIMalik (Manzar Iqbal Malik), @tc360950 (Tomasz Cąkała), @emsko, @SkalskiP (Piotr Skalski)
supervision-0.20.0
🚀 Added
-
sv.KeyPointsto provide initial support for pose estimation and broader keypoint detection models. (#1128) -
sv.EdgeAnnotatorandsv.VertexAnnotatorto enable rendering of results from keypoint detection models. (#1128)
import cv2
import supervision as sv
from ultralytics import YOLO
image = cv2.imread(<SOURCE_IMAGE_PATH>)
model = YOLO('yolov8l-pose')
result = model(image, verbose=False)[0]
keypoints = sv.KeyPoints.from_ultralytics(result)
edge_annotators = sv.EdgeAnnotator(color=sv.Color.GREEN, thickness=5)
annotated_image = edge_annotators.annotate(image.copy(), keypoints)
import cv2
import supervision as sv
from ultralytics import YOLO
image = cv2.imread(<SOURCE_IMAGE_PATH>)
model = YOLO('yolov8l-pose')
result = model(image, verbose=False)[0]
keypoints = sv.KeyPoints.from_ultralytics(result)
vertex_annotators = sv.VertexAnnotator(color=sv.Color.GREEN, radius=10)
annotated_image = vertex_annotators.annotate(image.copy(), keypoints)
🌱 Changed
-
sv.LabelAnnotatorby adding an additionalcorner_radiusargument that allows for rounding the corners of the bounding box. (#1037) -
sv.PolygonZonesuch that theframe_resolution_whargument is no longer required to initializesv.PolygonZone. (#1109)
Warning
The frame_resolution_wh parameter in sv.PolygonZone is deprecated and will be removed in supervision-0.24.0.
-
sv.get_polygon_centerto calculate a more accurate polygon centroid. (#1084) -
sv.Detections.from_transformersby adding support for Transformers segmentation models and extract class names values. (#1069)
import torch
import supervision as sv
from PIL import Image
from transformers import DetrImageProcessor, DetrForSegmentation
processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50-panoptic")
model = DetrForSegmentation.from_pretrained("facebook/detr-resnet-50-panoptic")
image = Image.open(<SOURCE_IMAGE_PATH>)
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
width, height = image.size
target_size = torch.tensor([[height, width]])
results = processor.post_process_segmentation(
outputs=outputs, target_sizes=target_size)[0]
detections = sv.Detections.from_transformers(results, id2label=model.config.id2label)
mask_annotator = sv.MaskAnnotator()
label_annotator = sv.LabelAnnotator(text_position=sv.Position.CENTER)
annotated_image = mask_annotator.annotate(
scene=image, detections=detections)
annotated_image = label_annotator.annotate(
scene=annotated_image, detections=detections)🛠️ Fixed
sv.ByteTrack.update_with_detectionswhich was removing segmentation masks while tracking. Now,ByteTrackcan be used alongside segmentation models. (#787)
🏆 Contributors
@onuralpszr (Onuralp SEZER), @rolson24 (Raif Olson), @xaristeidou (Christoforos Aristeidou), @jeslinpjames (Jeslin P James), @Griffin-Sullivan (Griffin Sullivan), @PawelPeczek-Roboflow (Paweł Pęczek), @pirnerjonas (Jonas Pirner), @sharingan000, @macc-n, @LinasKo (Linas Kondrackis), @SkalskiP (Piotr Skalski)
supervision-0.19.0
🧑🍳 Cookbooks
Supervision Cookbooks - A curated open-source collection crafted by the community, offering practical examples, comprehensive guides, and walkthroughs for leveraging Supervision alongside diverse Computer Vision models. (#860)
🚀 Added
sv.CSVSinkallowing for the straightforward saving of image, video, or stream inference results in a.csvfile. (#818)
import supervision as sv
from ultralytics import YOLO
model = YOLO(<SOURCE_MODEL_PATH>)
csv_sink = sv.CSVSink(<RESULT_CSV_FILE_PATH>)
frames_generator = sv.get_video_frames_generator(<SOURCE_VIDEO_PATH>)
with csv_sink:
for frame in frames_generator:
result = model(frame)[0]
detections = sv.Detections.from_ultralytics(result)
csv_sink.append(detections, custom_data={<CUSTOM_LABEL>:<CUSTOM_DATA>})traffic_csv_2.mp4
sv.JSONSinkallowing for the straightforward saving of image, video, or stream inference results in a.jsonfile. (#819)
import supervision as sv
from ultralytics import YOLO
model = YOLO(<SOURCE_MODEL_PATH>)
json_sink = sv.JSONSink(<RESULT_JSON_FILE_PATH>)
frames_generator = sv.get_video_frames_generator(<SOURCE_VIDEO_PATH>)
with json_sink:
for frame in frames_generator:
result = model(frame)[0]
detections = sv.Detections.from_ultralytics(result)
json_sink.append(detections, custom_data={<CUSTOM_LABEL>:<CUSTOM_DATA>})sv.mask_iou_batchallowing to compute Intersection over Union (IoU) of two sets of masks. (#847)sv.mask_non_max_suppressionallowing to perform Non-Maximum Suppression (NMS) on segmentation predictions. (#847)sv.CropAnnotatorallowing users to annotate the scene with scaled-up crops of detections. (#888)
import cv2
import supervision as sv
from inference import get_model
image = cv2.imread(<SOURCE_IMAGE_PATH>)
model = get_model(model_id="yolov8n-640")
result = model.infer(image)[0]
detections = sv.Detections.from_inference(result)
crop_annotator = sv.CropAnnotator()
annotated_frame = crop_annotator.annotate(
scene=image.copy(),
detections=detections
)supervision-0.19.0-promo.mp4
🌱 Changed
sv.ByteTrack.resetallowing users to clear trackers state, enabling the processing of multiple video files in sequence. (#827)sv.LineZoneAnnotatorallowing to hide in/out count usingdisplay_in_countanddisplay_out_countproperties. (#802)sv.ByteTrackinput arguments and docstrings updated to improve readability and ease of use. (#787)
Warning
The track_buffer, track_thresh, and match_thresh parameters in sv.ByterTrack are deprecated and will be removed in supervision-0.23.0. Use lost_track_buffer, track_activation_threshold, and minimum_matching_threshold instead.
sv.PolygonZoneto now accept a list of specific box anchors that must be in zone for a detection to be counted. (#910)
Warning
The triggering_position parameter in sv.PolygonZone is deprecated and will be removed in supervision-0.23.0. Use triggering_anchors instead.
- Annotators adding support for Pillow images. All supervision Annotators can now accept an image as either a numpy array or a Pillow Image. They automatically detect its type, draw annotations, and return the output in the same format as the input. (#875)
🛠️ Fixed
sv.DetectionsSmootherremovingtracking_idfromsv.Detections. (#944)sv.DetectionDatasetwhich, after changes introduced insupervision-0.18.0, failed to load datasets in YOLO, PASCAL VOC, and COCO formats.
🏆 Contributors
@onuralpszr (Onuralp SEZER), @LinasKo (Linas Kondrackis), @LeviVasconcelos (Levi Vasconcelos), @AdonaiVera (Adonai Vera), @xaristeidou (Christoforos Aristeidou), @Kadermiyanyedi (Kader Miyanyedi), @NickHerrig (Nick Herrig), @PacificDou (Shuyang Dou), @iamhatesz (Tomasz Wrona), @capjamesg (James Gallagher), @sansyo, @SkalskiP (Piotr Skalski)
supervision-0.18.0
🚀 Added
sv.PercentageBarAnnotatorallowing to annotate images and videos with percentage values representing confidence or other custom property. (#720)
import supervision as sv
image = ...
detections = sv.Detections(...)
percentage_bar_annotator = sv.PercentageBarAnnotator()
annotated_frame = percentage_bar_annotator.annotate(
scene=image.copy(),
detections=detections
)
sv.RoundBoxAnnotatorallowing to annotate images and videos with rounded corners bounding boxes. (#702)sv.DetectionsSmootherallowing for smoothing detections over multiple frames in video tracking. (#696)
supervision-detection-smoothing.mp4
sv.OrientedBoxAnnotatorallowing to annotate images and videos with OBB (Oriented Bounding Boxes). (#770)
import cv2
import supervision as sv
from ultralytics import YOLO
image = cv2.imread(<SOURCE_IMAGE_PATH>)
model = YOLO("yolov8n-obb.pt")
result = model(image)[0]
detections = sv.Detections.from_ultralytics(result)
oriented_box_annotator = sv.OrientedBoxAnnotator()
annotated_frame = oriented_box_annotator.annotate(
scene=image.copy(),
detections=detections
)
sv.ColorPalette.from_matplotliballowing users to create asv.ColorPaletteinstance from a Matplotlib color palette. (#769)
import supervision as sv
sv.ColorPalette.from_matplotlib('viridis', 5)
# ColorPalette(colors=[Color(r=68, g=1, b=84), Color(r=59, g=82, b=139), ...])
🌱 Changed
sv.Detections.from_ultralyticsadding support for OBB (Oriented Bounding Boxes). (#770)sv.LineZoneto now accept a list of specific box anchors that must cross the line for a detection to be counted. This update marks a significant improvement from the previous requirement, where all four box corners were necessary. Users can now specify a single anchor, such assv.Position.BOTTOM_CENTER, or any other combination of anchors defined asList[sv.Position]. (#735)sv.Detectionsto support custom payload. (#700)sv.Color's andsv.ColorPalette's method of accessing predefined colors, transitioning from a function-based approach (sv.Color.red()) to a more intuitive and conventional property-based method (sv.Color.RED). (#756) (#769)
Warning
sv.ColorPalette.default() is deprecated and will be removed in supervision-0.21.0. Use sv.ColorPalette.DEFAULT instead.
sv.ColorPalette.DEFAULTvalue, giving users a more extensive set of annotation colors. (#769)

sv.Detections.from_roboflowtosv.Detections.from_inferencestreamlining its functionality to be compatible with both the both inference pip package and the Roboflow hosted API. (#677)
Warning
Detections.from_roboflow() is deprecated and will be removed in supervision-0.21.0. Use Detections.from_inference instead.
import cv2
import supervision as sv
from inference.models.utils import get_roboflow_model
image = cv2.imread(<SOURCE_IMAGE_PATH>)
model = get_roboflow_model(model_id="yolov8s-640")
result = model.infer(image)[0]
detections = sv.Detections.from_inference(result)🛠️ Fixed
sv.LineZonefunctionality to accurately update the counter when an object crosses a line from any direction, including from the side. This enhancement enables more precise tracking and analytics, such as calculating individual in/out counts for each lane on the road. (#735)
supervision-0.18.0-promo-sample-2-result.mp4
🏆 Contributors
@onuralpszr (Onuralp SEZER), @HinePo (Rafael Levy), @xaristeidou (Christoforos Aristeidou), @revtheundead (Utku Özbek), @paulguerrie (Paul Guerrie), @yeldarby (Brad Dwyer), @capjamesg (James Gallagher), @SkalskiP (Piotr Skalski)
supervision-0.17.1
🚀 Added
- Support for Python 3.12.
🏆 Contributors
@onuralpszr (Onuralp SEZER), @SkalskiP (Piotr Skalski)
Contributors
Assets 2
supervision-0.17.0
🚀 Added
sv.PixelateAnnotatorallowing to pixelate objects on images and videos. (#633)
walking-pixelate-corner-optimized.mp4
-
sv.TriangleAnnotatorallowing to annotate images and videos with triangle markers. (#652) -
sv.PolygonAnnotatorallowing to annotate images and videos with segmentation mask outline. (#602)>>> import supervision as sv >>> image = ... >>> detections = sv.Detections(...) >>> polygon_annotator = sv.PolygonAnnotator() >>> annotated_frame = polygon_annotator.annotate( ... scene=image.copy(), ... detections=detections ... )
walking-polygon-optimized.mp4
-
sv.assetsallowing download of video files that you can use in your demos. (#476)>>> from supervision.assets import download_assets, VideoAssets >>> download_assets(VideoAssets.VEHICLES) "vehicles.mp4"
-
Position.CENTER_OF_MASSallowing to place labels in center of mass of segmentation masks. (#605) -
sv.scale_boxesallowing to scalesv.Detections.xyxyvalues. (#651) -
sv.calculate_dynamic_text_scaleandsv.calculate_dynamic_line_thicknessallowing text scale and line thickness to match image resolution. (#637) -
sv.Color.as_hexallowing to extract color value in HEX format. (#620) -
sv.Classifications.from_timmallowing to load classification result from timm models. (#572) -
sv.Classifications.from_clipallowing to load classification result from clip model. (#478) -
sv.Detections.from_azure_analyze_imageallowing to load detection results from Azure Image Analysis. (#571)
🌱 Changed
-
sv.BoxMaskAnnotatorrenaming it tosv.ColorAnnotator. (#646) -
sv.MaskAnnotatorto make it 5x faster. (#606)

🛠️ Fixed
-
sv.DetectionDataset.from_yoloto ignore empty lines in annotation files. (#584) -
sv.BlurAnnotatorto trim negative coordinates before bluring detections. (#555) -
sv.TraceAnnotatorto respect trace position. (#511)
🏆 Contributors
@onuralpszr (Onuralp SEZER), @hugoles (Hugo Dutra), @karanjakhar (Karan Jakhar), @kim-jeonghyun (Jeonghyun Kim), @fdloopes (
Felipe Lopes), @abhishek7kalra (Abhishek Kalra), @SummitStudiosDev, @xenteros @capjamesg (James Gallagher), @SkalskiP (Piotr Skalski)